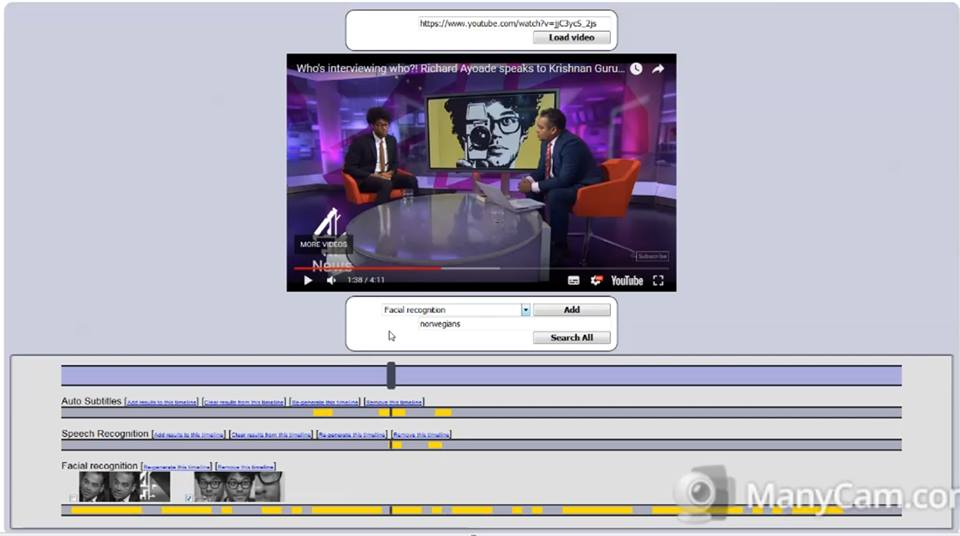
Cover image: Screenshot from the SiaVid front-end web interface
Check it out on GitHub
![]() SiaVid has been released for free use under the GNU General Public License, so feel free to have a poke and prod at the code.
SiaVid has been released for free use under the GNU General Public License, so feel free to have a poke and prod at the code.
So it’s been a little while since I’ve had a chance to update the blog, which has been largely down to me having to focus on University. One of the things I’ve had the pleasure of working on this year along side a couple of colleagues is an application which we’ve named SiaVid.
What does it do?
So SiaVid is an open source customisable Data Mining framework, which downloads and extracts different types of information from online videos, making the contents of a video searchable for users in interesting ways. So for example, if you wanted to know when person 2 appears in the video, saying the word “cheese”, you can combine a couple of search timelines to do just that, through the pretty graphical interface. So what’s under the hood?
The Pipeline Framework
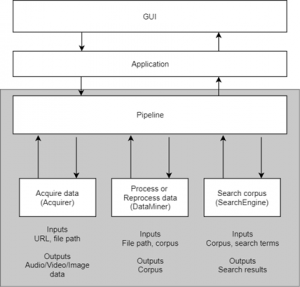
Illustration of how the pipeline interface might be used in an application.
Data processing and search functionality is made possible through three different broad types of plugins, these are Acquirers, Data Miners, and Search Engines. Acquirers are responsible for fetching certain types of data that might be required by Data Miners (e.g. images from a video, sound from a video etc.), one or more Data Miners process data retrieved by Acquirers to produce searchable data (a corpus) which can be searched with a particular Search Engine. A Pipeline holds all plugins necessary for an application, and a specific sequence of plugins can be defined in a Timeline object within the pipeline. For example the pipeline might contain an “AudioFromVideo” acquirer, a “SpeechRecognition” data miner, and a “TrieSearch” search engine, we could then create a Speech Recognition timeline from these plugins, which could then be activated by a user, allowing them to perform speech recognition on the video, and search the results. My own personal focus for this application was on the development of the Speech Recognition and Facial Classification functionality.
Speech Recognition Timeline
The Speech Recognition timeline included in the sample application is made up of an “AudioAcquirer” acquirer, which (yep, you guessed it) acquires audio from a given video link and saves it to a file, it then passes that file on to the “AudioSplitter” data miner which divides the audio file in to a series of smaller files (enabling us to perform speech recognition on multiple cores). The “SpeechRecognitionMiner” data miner takes the output from the audio splitter and generates a series of subtitle chunks, which are made searchable with the “chunkToRIDict”, which converts the subtitle chunks to their final searchable format. The result is the ability to search for a word, and be told at which time chunk(s) in a video that word appears.
Facial Classification Timeline

Example of two clusters created by the timeline for a video containing two individual people. In this case, 75% of images are clustered correctly, but we can see some mistakes as well as noisy images (pictures not of faces) brought forward from the facial detection stage.
This timeline consists of an image acquirer, which uses OpenCV to retrieve frames from a video as images, a Facial Detection data miner which uses Haar cascades to detect faces, and save images of them. A FaceClusterer data miner is then given all images of faces, and uses one of two unsupervised clustering algorithms to attempt to group the faces by similarity. The result is a number of clusters, which should hopefully represent individual people featured in the video. The Facial Classification functionality is somewhat experimental, it works very well under certain conditions, but not so well in others! As such, I still consider this a work in progress. In the best cases, if the FaceClusterer is told the number of people up front, it correctly clusters 75% of images, and if you let it work out the number of people for it’s self, it correctly clusters images only 54% of the time.
A Closer look at Speech Recognition and Facial Classification
I feel like I’ve barely been able to scratch the surface of these two tasks in this article, so I’ll be writing some more detailed articles over the coming weeks, where I intend to cover:
- How speech in audio is interpreted by a computer
- Modern tools and models for speech recognition
- Methods of evaluating speech recognition
- How to represent faces in a computer for facial classification (facial feature encoding)
- Supervised and unsupervised image classification
- How to evaluate unsupervised classification methods
As always thanks for reading, and if you have any questions or comments, feel free to leave them below, I always appreciate feedback.