
This article is based on a draft of my paper “A Review of Distributional Semantic Modelling Methods in Natural Language Processing”, which can be found below.
On Twitter, an average of 350,000 tweets are posted per minute (that’s 500 million per day, 200 billion tweets per year). Data on sites such as this, e-commerce sites, review sites and many more, contain opinions on a variety of entities and products from real people across the globe, information on what the hottest topics are within various regions and demographics, but it also contains a lot of irrelevant information. Sifting through all this data manually isn’t really feasible, this is where the appeal of Natural Language Processing (NLP) really shines through.
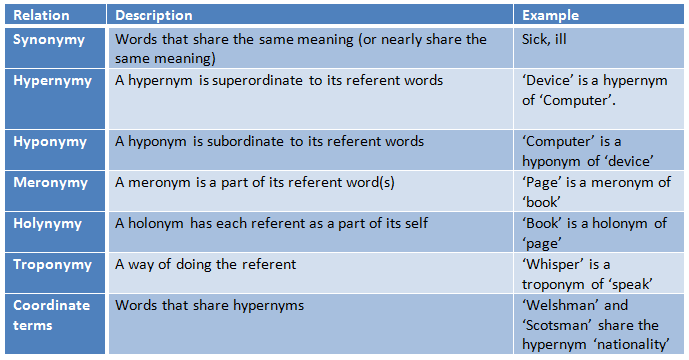
A table describing some of the different types of semantic relationships that can occur between words.
One of the biggest, most challenging problems in NLP is how to model the relationships between words of a language, and the many different relationships between words (see word relationship table). For example if we’re looking at how people feel about chocolate, intuitively we know the words “good, great, amazing, fantastic” are synonymous, they all indicate a positive sentiment, but how can we get a computer to consider these words as being similar? This could be, and has been, done manually by a group of linguists, WordNet is an example of this. WordNet is a database which models different kinds of relationships between words including (but not limited to) synonymy and hypernymy. While WordNet is an incredibly powerful tool which has been used very successfully across many applications, it doesn’t include industry specific jargon and slang terms. Not to mention that language, and meaning associated with words is constantly evolving, sometimes in different ways across different regions, generations, and cultures.
Enter Distributed Semantic Modelling (DSM), this is a family of techniques based around the Distributional Hypothesis (DH), which states that the similarity in meaning (or semantic similarity) between one word and other words across a large collection of texts, can be determined by how often they appear together within the same context. To put it another way, this is essentially having a computer learn the semantic properties of words from experience, in the same way that a person may benefit from hearing a word used in several sentences to better understand it. So for example if we’re looking at the words “cat”, “dog” and “rock”, and the words that appear near them across all books in a library, we might find that the words “cat” and “dog” appear in similar contexts, with words like “feed”, “tail”, “pet”, where as the word “rock” is less likely to appear with these words, from this we could deem that the words “cat” and “dog” are semantically similar in some way, and the word “rock” is semantically distant from these words.
Can we Truly Capture Meaning with these Methods?
A key issue in the study of meaning in language is defining precise, methodological criteria for the semantic content of words, and expressing the conditions in which words share similar meaning. One of the key players in devising the DH (Zellig Harris), associated meaning with the general characteristics of human activity, rather than being a property of language its self. He described the relationship between meaning and language as a complicated one which doesn’t always conform to subjective experience. So as an example, while a persons experience and perceptions of the world might change over the years, their choice of language will often remain pretty consistent. Not to mention the experiences and feelings we get that we can’t always find the words to fully describe with the language available to us. As mentioned earlier, meaning in words is not at all static, as many factors across time can affect meaning. So while methods making use of the DH does give some insight into the semantic similarity/relationships between words, it does not explain/reveal meaning its self, which some believe will remain out of reach for linguists. Even so, the relationships highlighted by distributional analysis have been leveraged very effectively across a variety of applications, including machine translation, but we’ll get to that in a minute.
Properties and Applications of Distributed Semantic Modelling
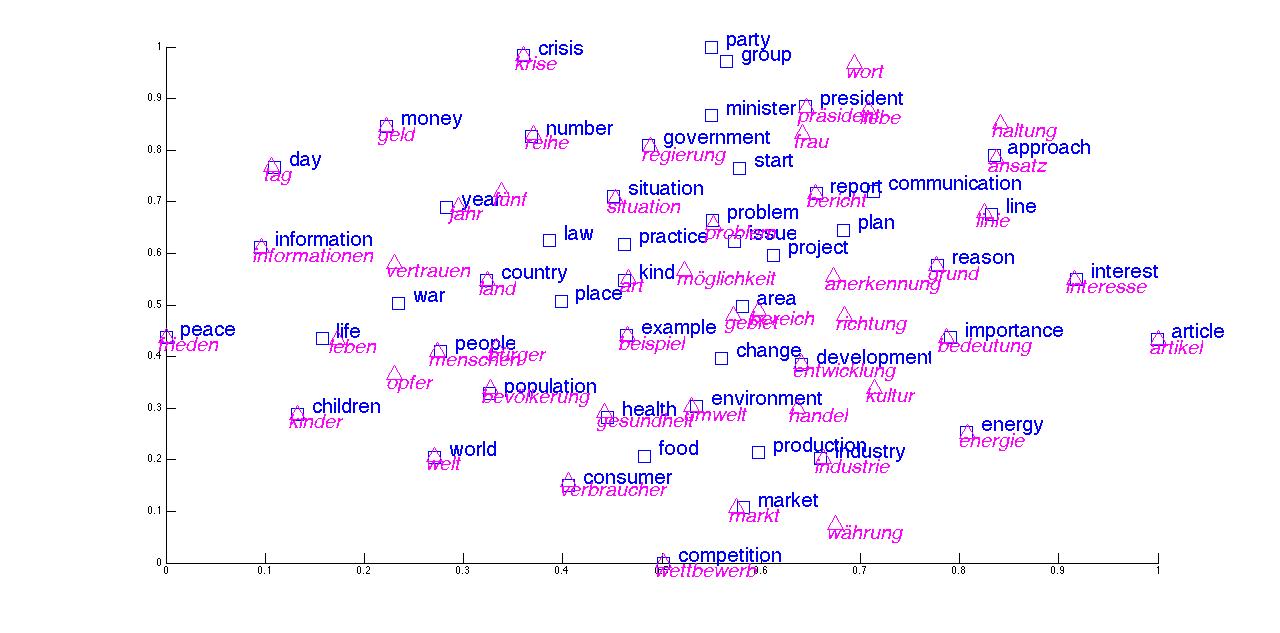
The DSM process at its core, involves creating a “vector space” out of all words in a series of texts. This can essentially be thought of as a map or environment, where each word in the environment has its own set of co-ordinates, described by vectors. Words appearing frequently in the same contexts will be closer together in this environment, while words not appearing in the same contexts will be further away from each other, which often reflects semantic similarity. Another interesting property of this environment, is how other relationships like male/female, or plural/singular relationships can present themselves with consistent distances or offsets within this environment (see figure above). For example, in this exploration of a distributed semantic model, they find that the following equation: King – Man + Woman with the co-ordinate vectors corresponding to these words, results in a co-ordinate vector almost equal to that of the word Queen. It’s these very properties in these models that are successfully exploited in machine translation, whereby multilingual environments or models can show similarities between words in different languages (see below illustration). It can also be seen that in some cases, synonymous terms appear closer together in these spaces, for example the words/vectors “party”, “group”, “minister”, “president”, and “government” are all very close together, almost forming a cluster. While the words “peace” and “interest” are somewhat distant from this cluster, take from that what you will…
Conclusion
DSM methods based on the DH show great promise across a variety of application areas, they can and have lead to improvements in machine translation, smarter search results, and more intuitive sentiment analysis. In future articles, I will take a more technical approach to the topic, with some tutorials on how to effectively build and use distributional language models.
James Barnden (13018604) A Review of Distributional Semantic Modelling